5 Legacy of Colonial Medicine
5.1 Colonial Medicine Intro
Between 1921 and 1956 French colonial governments in Africa organized medical campaigns to treat and prevent sleeping sickness. Sleeping sickness is a lethal parasitic disease transmitted by the bite of a tsetse fly, which inhabit certain areas of Africa. During the colonial era, French colonies had military-organized campaigns exclusively focused on treating sleeping sickness.
However, the treatments at the time (Atoxyl and Lomidine) both were questionable in their efficacy and had severe side effects. Historians and anthropologists have linked sleeping sickness campaigns to mistrust in modern medicine.
In this section, we will use data from Lowes and Montero (2021) to study how colonial medical campaigns undertaken generations ago impact health behaviors today. To do so, we will use measures of exposure to medical campaigns constructed by Lowes and Montero (2021) from newly digitized military records from France.
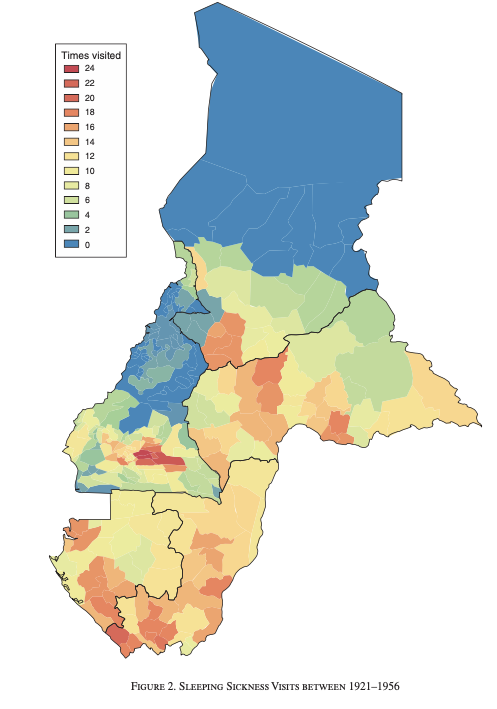
Figure 5.1: Sleeping Sickness Visits Between 1921-1956
Figure 5.1 shows the variation in sleeping sickness across areas in Cameroon and French Equatorial Africa (present-day Central African Republic, Chad, Republic of Congo, and Gabon). As can be seen in the figure, there is large variation across areas. Some places (in blue), had no medical campaign visits related to sleeping sickness during this period. Other areas (red), were visited as many as 24 times in the years between 1921-1956. We will study how variation in these visit rates correlates to measures of trust in medicine today.
In Lowes and Montero (2021), the authors study two key outcomes, both of which come from Demographic and Health Surveys (DHS). The first is a vaccination index that captures what fraction of possible vaccines children have received. The second studies whether individuals refuse a free, non-invasive blood test. Consent to the blood test is high in these samples, as the blood test is taken by finger prick and is free to the individuals in the survey. Refusal of this blood test might then signal distrust in medicine generally.
To begin, let's load the dataset colonial_medicine.dta
cd "/Users/davidarnold/Dropbox/Teaching/EP5/online/05_week/data"
use colonial_medicine.dta, replace
/Users/davidarnold/Dropbox/Teaching/EP5/online/05_week/dataAs usual, let's describe the data to learn more about the variables.
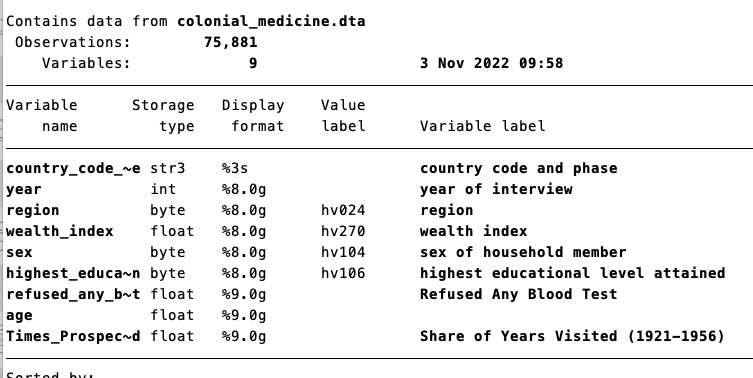
Figure 5.2: Describing the Colonial Medicine Data Set
So we have 75,881 survey participants, some demographics of the individual, a key outcome variable (refused_any_blood_test), as well as a key explanatory variable (Times_Prospected). To understand our key variables, let's first summarize our outcome variable.
This data is at the individual level and includes some basic demographics (age, sex, etc.) as well as our key outcome: refused_any_blood_test
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
refused_an~t | 11,993 .1110648 .3142255 0 1So around 11 percent overall refuse a blood test. Our goal will be to understand if this refusal rate depends on how often an individual's area was visited during sleeping sickness campaigns in the past. The variable that captures this is Times_Prospected:
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
Times_Pros~d | 67,036 .2941624 .1943945 0 .8So a value of 0.2 indicates on average, an individual's location was visited 20 percent of the years between 1921-1956 (35 years total). In simpler terms, a value of 0.2 indicates 7 years, because 7 is 20 percent of 35.
So we now have the data to answer our initial question: are people who live in places in which historical medical campaigns were more prevalent more likely to refuse blood tests today? But first, let's highlight a few new aspects of the data that we will need to understand.
First, if I browse the data, you will see the variable wealth_index looks like it is a string variable, yet it is highlighted in blue, not red

Figure 5.3: Value Labels for Wealth Index
If we take the average of wealth_index, we do get a number out
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
wealth_index | 75,881 3.212319 1.43691 1 5We will discuss this behavior in a future chapter about value labels. Next, If I browse the data, you will see the variable refused_any_blood_test has some missing values (the period indicates the value is missing).
Figure 5.4: Missing Values
It is important to be careful about missing values generally, but particularly in Stata, which we will discuss in a future chapter as well. So before we get to answering our main question, we first need to handle these data issues.
5.2 Value Labels
A value label associates a description with a particular numeric value of a variable. Sometimes it is convenient to store variables as numeric, for example, if we would like to apply some mathematical operations. However, it might be hard to remember what each value of the data represents. Value labels allow you to store the information as numeric, while still being able to quickly reference what each number represents.
In order to discuss value labels, we are going to look at the American National Election Survey. The American National Election Survey (ANES) is a survey on elections in the U.S. It has a large range of questions that come in the survey. To make it easier for users of the dataset, many of the variables have value labels attached.
We are going to load a very small subset of the dataset which has information on just a few questions:
If we browse the data, we can see some of the variables have value labels.
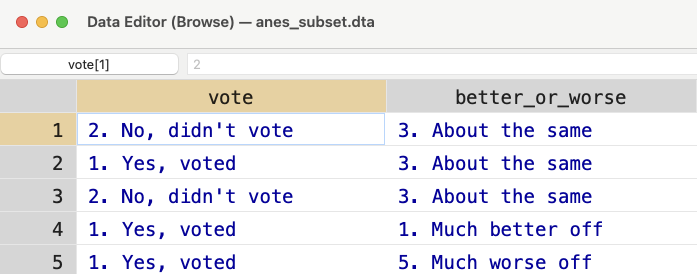
Figure 5.5: Browsing the ANES
For vote and better_or_worse the values look like characters, but they are highlighted in blue instead of red. What is going on? If we look closely, we can see the actual value associated with a given cell. For example, in Figure 5.6, I have clicked the first cell in the table. As you can see the highlighted value is equal to 2. This is the value in the table.
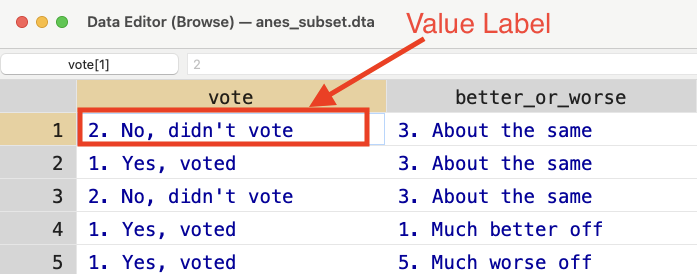
Figure 5.6: Browsing the ANES
The value label is the text highlighted in blue ("2. No, didn't vote"). If we use tab we can see the different values labels for a given variable. Let's try this for vote:
tab vote
PRE: Did R vote for |
President in 2012 | Freq. Percent Cum.
--------------------------+-----------------------------------
-9. Refused | 2 0.05 0.05
-8. Don't know (FTF only) | 14 0.33 0.37
1. Yes, voted | 3,117 73.00 73.37
2. No, didn't vote | 1,137 26.63 100.00
--------------------------+-----------------------------------
Total | 4,270 100.00So there are 4 different value labels. If you need to reference values of these variables, you need to use the actual numeric values, not the labels themselves. The labels are just there so we don't forget what the numbers mean. For example, if I wanted to see how many individuals refused the question, I can type:
If I try to do the same thing, but referencing the value label, I will get an error:
It states type mismatch because vote is a numeric variable, not a string variable. A quick way to see the numeric values associated with the labels is to type:
tab vote, sum(vote)
PRE: Did R |
vote for | Summary of PRE: Did R vote for
President | President in 2012
in 2012 | Mean Std. dev. Freq.
------------+------------------------------------
-9. Refus | -9 0 2
-8. Don't | -8 0 14
1. Yes, v | 1 0 3,117
2. No, di | 2 0 1,137
------------+------------------------------------
Total | 1.2320843 .72453319 4,270Concept Check
Make sure you understand why the above code can retrieve the numeric value associated with each label. Remember, tab creates a table of frequencies, while sum generates summary statistics.
5.3 Missing Values
Continuing our exploration of the ANES dataset, we will now discuss missing values. For numeric variables, Stata stores missing values as a period. If your numeric variable does not code missing information as a period, then you should change this before continuing the analysis. To see why, let's consider the variable better_or_worse, which asks the respondent on a scale of 1 to 5 how much worse off are you relative to a year ago.
PRE: R how much better |
worse off than 1 year ago | Freq. Percent Cum.
--------------------------+-----------------------------------
-9. Refused | 11 0.26 0.26
-8. Don't know (FTF only) | 2 0.05 0.30
1. Much better off | 298 6.98 7.28
2. Somewhat better off | 904 21.17 28.45
3. About the same | 1,981 46.39 74.85
4. Somewhat worse off | 763 17.87 92.72
5. Much worse off | 311 7.28 100.00
--------------------------+-----------------------------------
Total | 4,270 100.00You can see that -8 and -9 are actually missing values, but right now they are stored as numbers. If I take the average of better_or_worse, I get:
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
better_or_~e | 4,270 2.937002 1.176809 -9 5But this average incorporates those values of -9 and -8. In terms of the scale of the variable, this will lower the overall average, which could lead to some pretty misleading results. For example, imagine instead of storing the missing values as -9, they were stored as -1000. Then, even though there are a few individuals with missing data, our average value of better_or_worse might be very low, as low as 1. If we naively took this as the average, then we might conclude that on average, people report they are much better off. But this is the wrong conclusion, we need the average response among individuals that actually answered the question.
What we need to do is replace individuals that have either a value of -8 or -9 to missing. To do this we can make use of the or operator, which is given by the symbol |. The code below will replace the value of better_or_worse to missing if the current value is either -8 or -9.
Now when we take the average, the missing values are not incorporated
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
better_or_~e | 4,257 2.972986 .9814891 1 5When you compute summary statistics or run regressions, observations with missing values will be dropped automatically from this calculation. However, you need to be very careful when constructing new variables from observations with missing values. For logical statements in Stata (such as when creating indicator variables), the missing value is interpreted as infinity. The reason why it was chosen to have missing values be interpreted as infinity is a little complicated, but it can lead to some confusing errors!
To see how, imagine we want to create an indicator that is equal to 1 if an individual thinks their life has gotten worse relative to 1 year ago. An individual that responded 4 or 5 believes their life has gotten worse relative to 1 year ago. So one potential way to code this new variable would be to type:
Let's see what worse_off is equal to for individuals that had missing values for better_or_worse.
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
worse_off | 13 1 0 1 1It is equal to 1 for all of these individuals, but why? The reason is missing values are interpreted as infinity in logical statements. Because infinity is greater than 4, then everyone with missing values of this is coded as worse_off=1.
To avoid this problem, we need to change the code so that it takes into account the possibility of missing values. For example, we might want to replace worse_off equal to missing if better_or_worse is equal to missing.
5.4 Binned Scatterplots (Theory)
In this chapter, we will discuss a new data visualization technique known as binned scatterplots. To understand this technique, let's first take a simple example. Imagine, we have the dataset below in Figure 5.7 which shows Earnings (vertical axis) against test scores (horizontal axis):
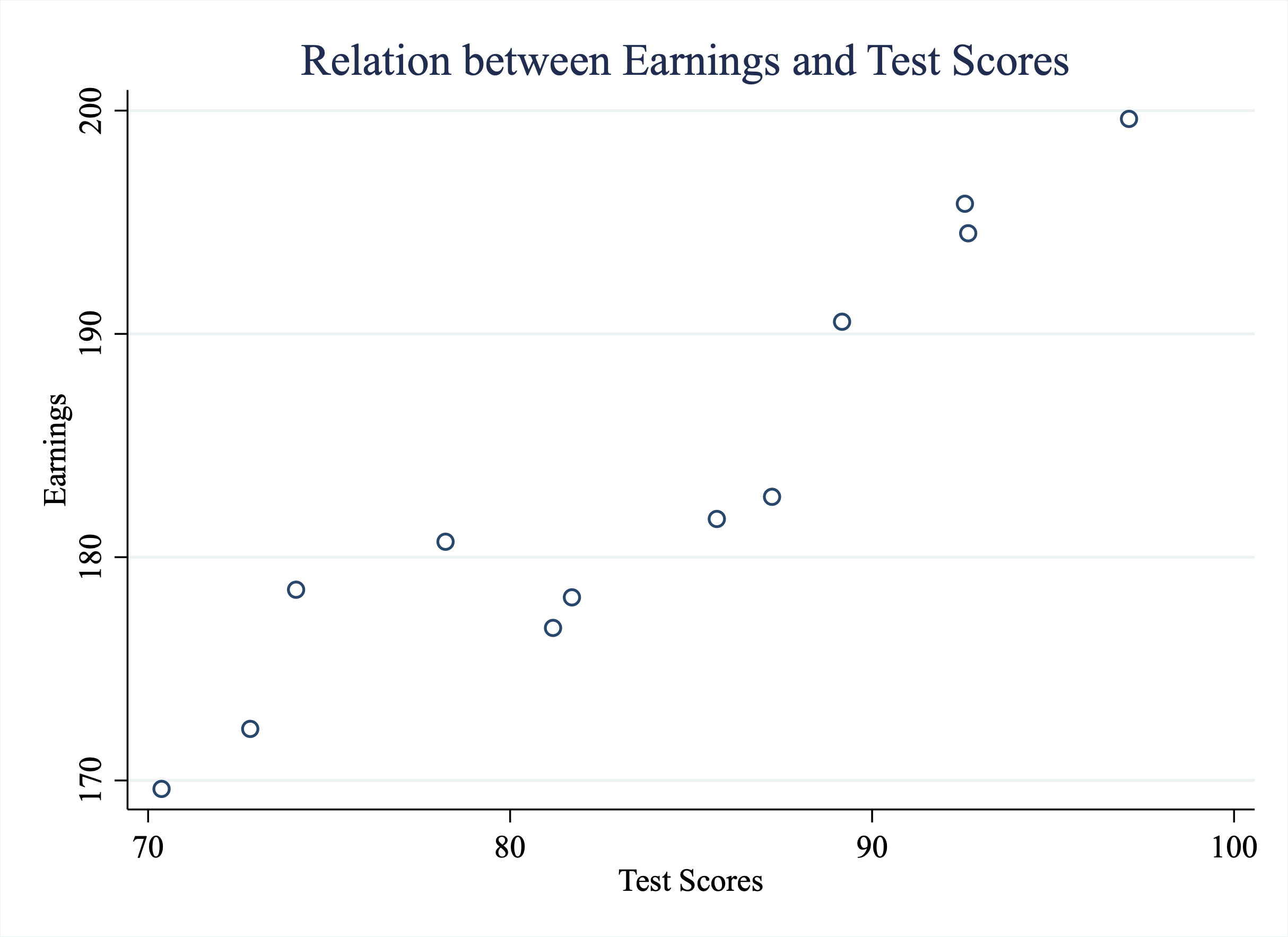
Figure 5.7: Relationship Between Earnings and Test Scores
In this example, we have plotted all the data and can clearly see that there is a positive relationship between test scores and earnings. Individuals with higher test scores tend to also have higher earnings. But what if there were 1,000 people in this dataset, or 10,000, or a million? The graph would soon get pretty crowded. Not only would a graph with a million observations be difficult to interpret, but it would also likely crash your computer!
However, instead of plotting all the data, imagine we bin the data into intervals. For example, in Figure 5.8 we have binned the data into intervals by dividing the x-axis into three bins. In bin 1 there are observations with scores below 80. Bin 2 has observations with scores between 80 and 90. Bin 3 has scores above 90.
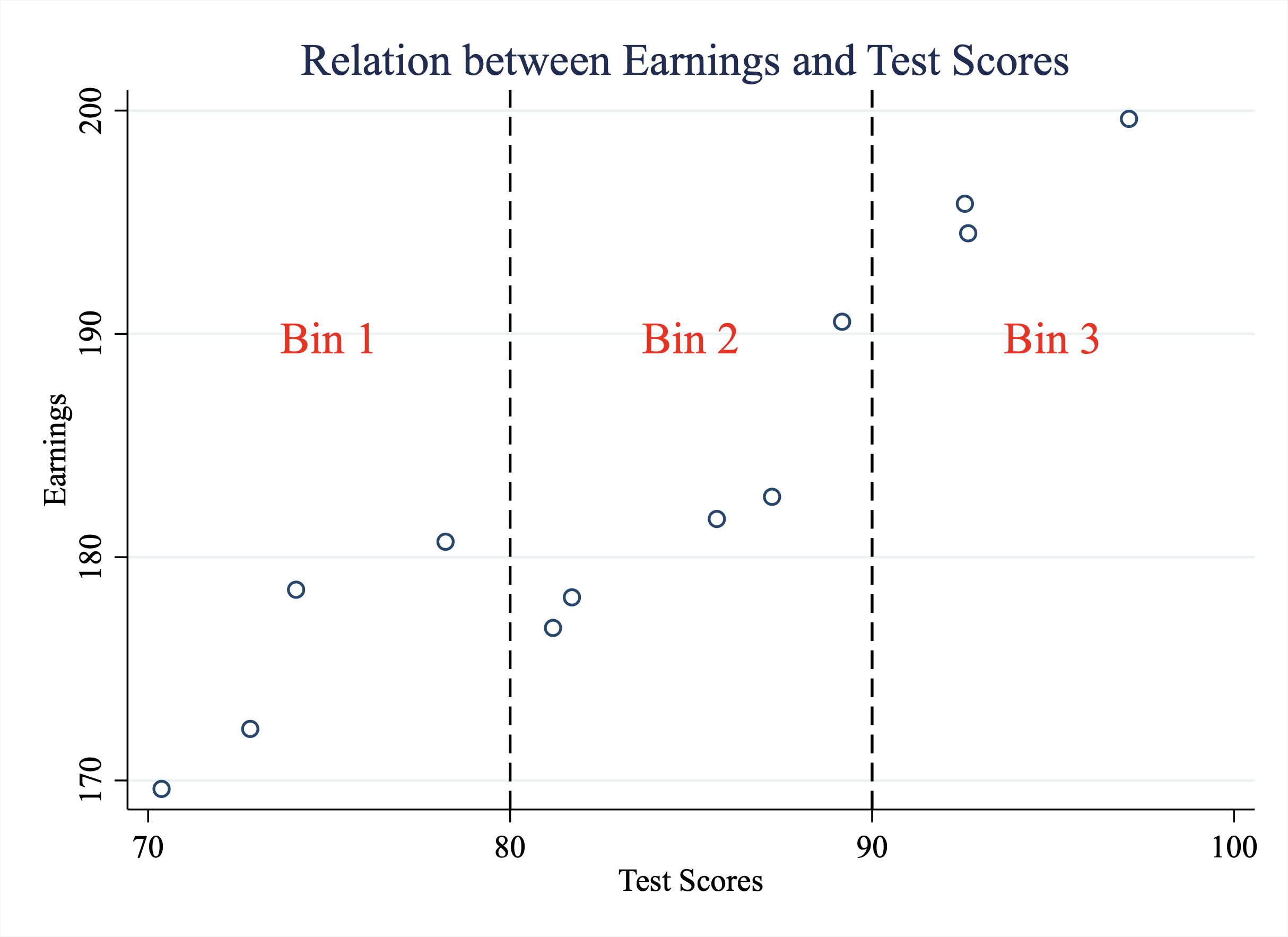
Figure 5.8: Binning the Data
Now instead of plotting all the data, let's just plot the averages within each bin, as depicted in Figure 5.9
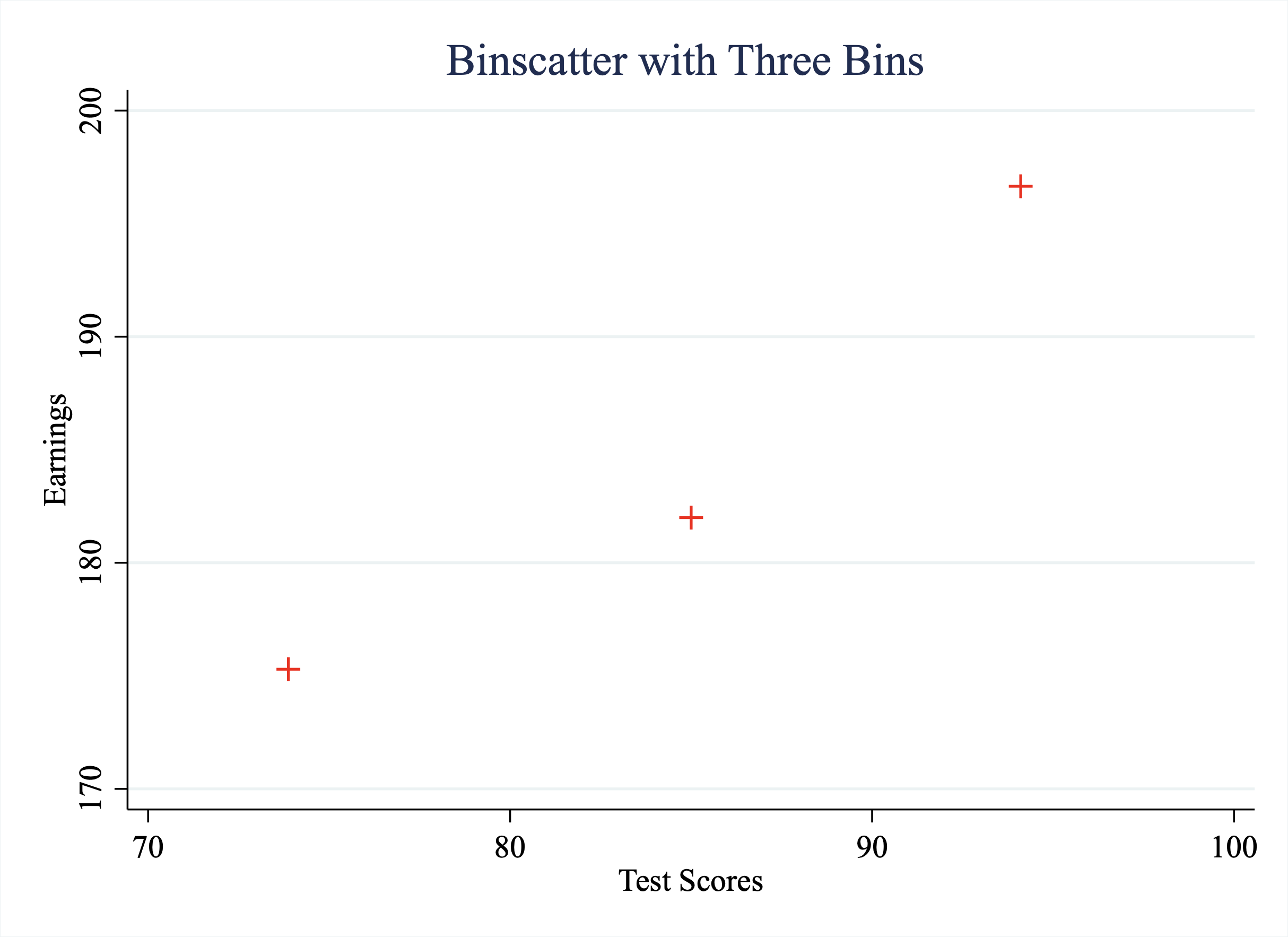
Figure 5.9: An Example of a Binned Scatterplot
This binned scatterplot allows us to transparently observe the relationship between two variables. However, now imagine we had 1000 students instead of the original 12. Well, the binned scatter plot will still have only 3 points. Note the decision to bin the data into three intervals was merely for illustrative purposes. In general, you can decide on how many bins to create. The key here is that even if the sample size grows, we can still show the relationship between these two variables in a binned scatterplot. Even if our sample size grows to a million, the number of points in the graph is still determined by the number of bins.
5.5 Binned Scatterplots (Stata)
In this section, we will use the data from Lowes and Montero (2021) to implement a binned scatterplot to study the legacy of colonial medicine in Africa. In order to construct the binned scatterplot we will make use of the binscatter command.
As a reminder, between 1921 and 1956, French colonies in Africa were visited by many medical campaigns often forcing medical care with questionable efficacy and severe side effects. Some places were visited only a small fraction of the years. Other places were visited often in these years. Are people who lived in places with many medical campaigns more likely to distrust medicine today?
To begin let's load the dataset:
cd "/Users/davidarnold/Dropbox/Teaching/EP5/online/05_week/data"
use colonial_medicine.dta, replace
/Users/davidarnold/Dropbox/Teaching/EP5/online/05_week/dataFirst, we need to drop values that either have missing information for refused_any_blood_test or Times_Prospected. refused_any_blood_test is our key outcome and is equal to 1 if the individual refused the free blood test and zero otherwise. Times_Prospected is our key explanatory variable and captures what fraction of years between 1921-and 1956 was the individual's region visited for sleeping sickness campaigns. If either of these values are missing for an observation, then they should not be included in the analysis.
The parallel line | indicates "or". So put simply, this line says to drop any observations in which either refused_any_blood_test or Times_Prospected is missing.
Next, we will use an external command named binscatter can be used to produce binned scatterplots. To install on your version of Stata, you first need to type.
Once you execute the code above once, then you will be able to use the binscatter command. The basic syntax of the binscatter command is:
In this syntax, you will replace yvar with whatever variable you want to plot on the vertical axis and xvar with whatever variable you want to plot on the horizontal axis. You will replace # with however many bins you want to create.
In our example, we want to understand the relationship between refusing to take a blood test (y-axis) and share of years visited by medical campaigns between 1921-1956 (x-axis). For illustrative purposes, let's specify nquantiles(10) which implies we will have 10 bins in our scatterplot. One nice thing about the binscatter command is that we can utilize everything that we've learned from creating graphs generally. In other words, let's make sure our graph has appropriate titles and axes labels.
binscatter refused_any_blood_test Times_Prospected, nq(10) ///
title("Binscatter: Refusing Blood Test vs. Share of Years Visited") ///
xtitle("Share of years visited, 1921-1956") ///
ytitle("Refused any blood test")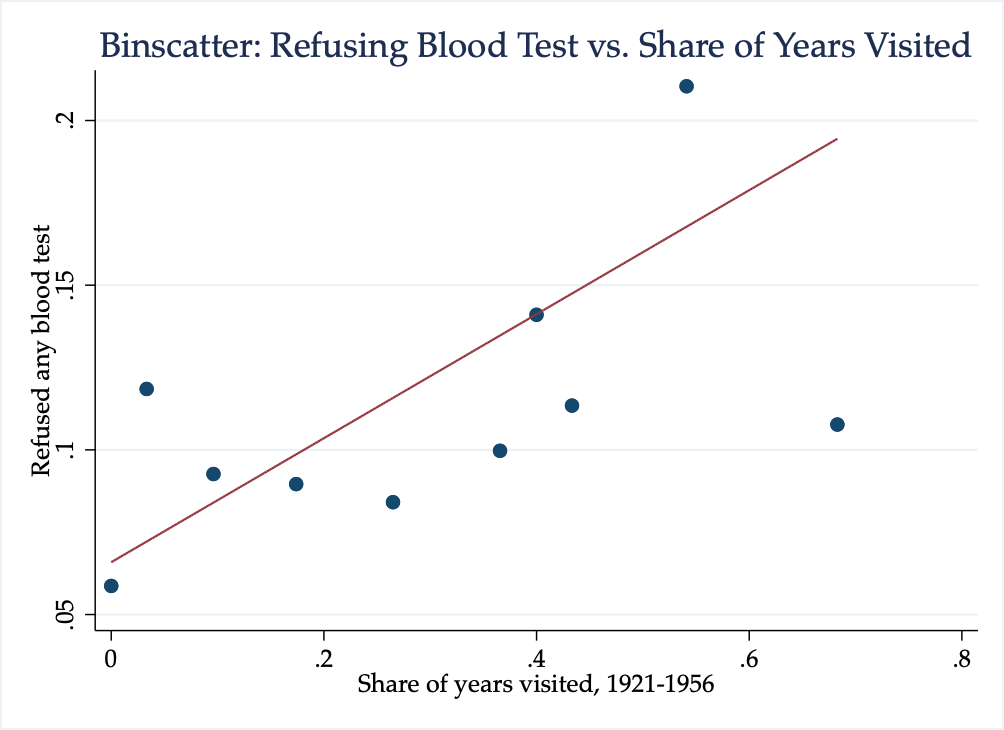
Figure 5.10: Binscatter: Refusing Blood Test vs. Share of Years Visited
As we can see from the graph, as the share of years visited increases, the fraction of individuals who refuse a blood test also increases. This provides supporting evidence for the initial hypothesis: areas that have a history of colonial medicine still distrust medicine today. The line depicted in the binned scatterplot is a regression line that shows the strength of this relationship.
It is also helpful for interpretation to retrieve the slope of this regression line. We can get this parameter by specifying reportreg as an option for our binscatter command.
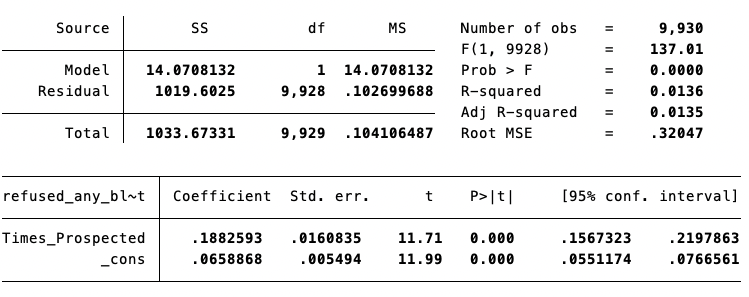
Figure 5.11: Regression Line: Refusing Blood Test vs. Share of Years Visited
Concept Check
From this regression line, we can conclude that an increase in 7 years of medical campaign visits is associated with a 3.8 percentage point increase in the rate of blood test refusal. If you understand (1) the scale of the variables and (2) the slope coefficient, you should be able to convince yourself this is true.
Hint: Remember that a 1-unit change in the X-variable is associated with a \(\beta\)-unit change in the Y-variable. The hardest thing about this problem is understanding the units of the X and Y variables in this example.
5.6 Conclusion
In this final section, we will summarize what we have learned so far and then present additional results from Lowes and Montero (2021). The goal of Lowes and Montero (2021) is to understand how medical campaigns in Africa between 1921 and 1956 impact perceptions of medicine today. Colonial medical campaigns undertaken to prevent sleeping sickness often forced medical treatment. The treatments both had questionable efficacy and came with severe side effects. Lowes and Montero (2021) utilize newly digitized French military records in order to measure the exposure of a region to medical campaigns in the past, and combine this information with health surveys to understand the impact of past campaigns on health behaviors today.
What we have explored is how exposure to these campaigns impacted the choice to refuse a blood test. While this blood test was free to survey participants and had an overall high takeup, some individuals rejected the blood test. This could be one proxy for trust in modern medicine. We found in the prior section that areas with more exposure to medical campaigns were more likely to refuse the blood test.
One thing you may notice if you read Lowes and Montero (2021), however, is that our results don't appear exactly the same as those in Lowes and Montero (2021). One reason is that Lowes and Montero (2021) also control for other potential factors that could be correlated with historical exposure to medical campaigns as well as health behaviors today. Maybe places with more exposure to colonial medical campaigns vary along a number of dimensions, and these other dimensions could explain the correlation we found. Turns out, you can estimate binned scatterplots that control for other factors. Doing so goes beyond this course, but in Lowes and Montero (2021) the authors control for other factors that impact health decisions, such as age, gender, urban-rural status, among others. Figure 5.12 displays the binned scatterplot we constructed while also controlling for these factors.
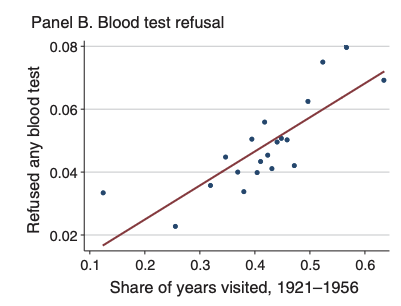
Figure 5.12: Binscatter: Refusing Blood Test vs. Share of Years Visited
Lowes and Montero (2021) also study if colonial medical campaigns impact vaccination rates today. To do so, they construct a vaccination index, which is the share of completed vaccines (out of 9) for children under 5. Again, they found places with more years of colonial medical visits have lower vaccination rates, as shown in Figure 5.13.
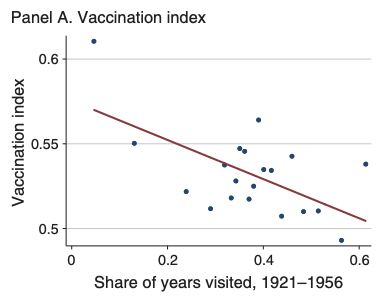
Figure 5.13: Binscatter: Vaccination vs. Share of Years Visited
This paper finds that negative experiences in the past were transmitted across generations. This finding has important implications for trust in institutions generally. It also has very real policy implications. Lowes and Montero (2021) find World Bank projects related to health are less successful in areas with high exposure to colonial medicine.
Command Descriptions
Commands Descriptions
-
binscatter yvar xvar, nquantiles(#)- creates a binned scatter plot withyvaron the vertical axis,xvaron the horizontal axis.nquantiles(#)determines how many bins will be created in the final scatter plot. For examplenquantiles(10)specifies 10 bins.
More Concepts
value labels - a value label is a string text associated with the particular numeric value of a variable. This is often useful for categorical variables. Having the variable be numeric allows you to perform mathematical operations on the variable, but having a label lets you easily interpret what each numeric value represents.
missing values - a missing value for a numeric variable in Stata is stored as a period. Be careful about using relations with respect to missing variables. For example, imagine you want to create a binary indicator that is equal to 1 if an individual is above the age of 40. You might type
gen above_40 = (age>40). If there are individuals with ages that are missing, thenabove_40will be equal to 1 for these individuals. To replace it back to missing, you can typereplace above_40 = . if age==..