6 Resume Experiments
6.1 Correspondence Studies
The motivation for this week's empirical application is the pervasive evidence of inequality in the labor market. For example, Black workers are about twice as likely as white workers to be unemployed (Council of Economic Advisors, 1998). However, it is often difficult to isolate discrimination from employers as a source of a given disparity. For example, some argue researchers do not have all factors that go into an employer's decision to hire a worker, therefore differences in hiring rates across different races could be due to these other factors that are unobserved.
This week we will be studying an extremely clever method for identifying discrimination in the labor market: resume audit studies, also known as correspondence studies. The paper we will be studying is Bertrand and Mullainathan (2004)8 sends fictitious resumes to help-wanted ads in Boston and Chicago. Their unique angle is that they manipulate the perception of race by altering the name on the resume:
Examples of white-sounding names from the paper: Emily Walsh and Greg Baker
Examples of Black-sounding names from the paper: Lakisha Washington and Jamal Jones
All other characteristics of the applicant (experience, education, job history) are randomized. They then compare callback rates (for an interview) between Black and white applicants.
Why is this design so clever? Well, all factors relevant to a job are held fixed by construction. Disparities in callback rates between races can no longer be "explained away" by other factors. The researchers themselves have generated these resumes. All factors are observed and similar between white and Black applicants by construction. Therefore, if you do find a disparity now, then this is very strong evidence for discrimination in the labor market.
Before getting to the data though, we need to learn how to use the program we will be studying for the rest of the book: R. At this point, we would also like to credit Kosuke Imai's Textbook: Quantitative Social Science: An Introduction, where this example is drawn from.9
6.2 Installing R/RStudio
In this course, we will be using R and Rstudio. R and Rstudio will work together to perform data analysis. But why two programs instead of one?
R is the software that actually does all the work. It is the software that executes functions and gives you results. Rstudio is a software that provides a nice interface through which to use R. So basically, R is the actual machinery, Rstudio is there to improve your user experience. You don't strictly need Rstudio to use R, but it helps a lot! Whenever we "open R" in this course, we will actually be opening RStudio.
Because RStudio doesn't work without R, the first thing we need to do is download R. To do this you can go to https://cran.r-project.org/ and download the most recent version of the software. R is available for both PC and Mac users. Once you download the package you can install it by following the instructions on the installer. One part of the instructions that sometimes trips up students is that you need to decide on a location for a CRAN mirror. The general advice for this is to choose the CRAN mirror in closest physical proximity to you. This is to potentially improve the download speed and balance resources across different servers. In practice, you really don't have to worry about this decision. Any CRAN mirror will allow you to download an identical version of R.
6.3 RStudio Interface
When you open RStudio, you will be greeted by the RStudio Interface depicted below in Figure 6.1
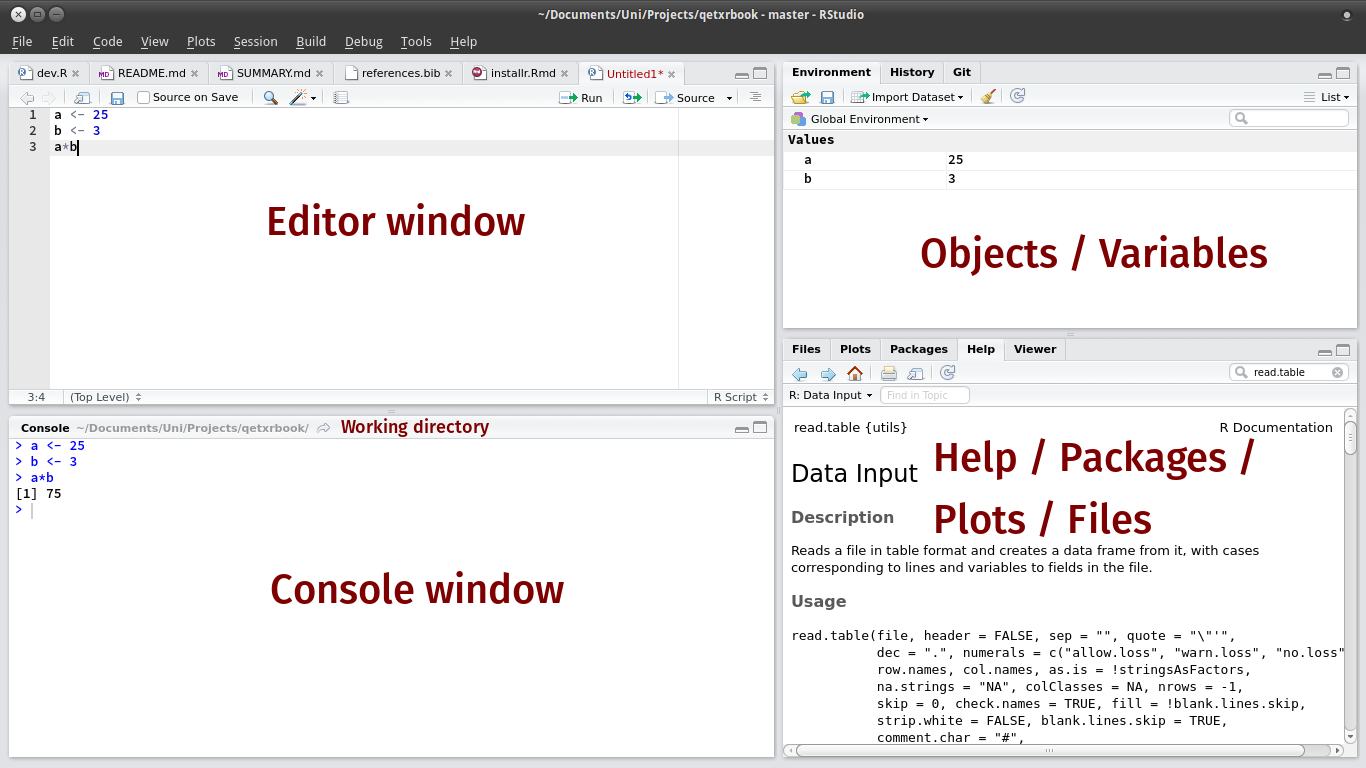
Figure 6.1: R Studio Interface
Let's discuss these 4 windows in turn. In the top left is the Editor Window. This is where you will write an R script that holds all of your code. You may not see this window initially if you have not yet opened an R script (which is the equivalent to a do-file in Stata). To open up a new R script you can go to File > New File > R Script.
Below the Editor Window is the Console. This is where all your code will be executed and run. For example, if you write code to take the average of a variable in the Editor Window, when you execute that code, the result will be displayed in the Console.
In the top right, we have the Environment, which is going to store objects, variables, and datasets. We will get more into what an object is further into the chapter.
Lastly, the bottom right window has a host of tabs that will be helpful. One that we will use frequently is the Plots tab. This is where the figures that we create in R will be displayed. Another important tab is the Packages tab. Further in this chapter, we will discuss the importance of packages in R. Lastly, we will also use the Help tab frequently. In this tab, you can search for documentation on how to use certain functions in R. This is similar to the help files that we often used in the Stata chapters.
So now that we understand the different components of the interface, we are going to get started with coding in R. The first thing to do is open a new R script. As discussed above, to do this, you can navigate to File > New File > R Script.
Now, in the R script, type:
5+3This line of code computes the sum of 5 and 3. To execute it, you have a few options. The first way to do this is to highlight the code, then press the Run button at the top right of the Editor window.
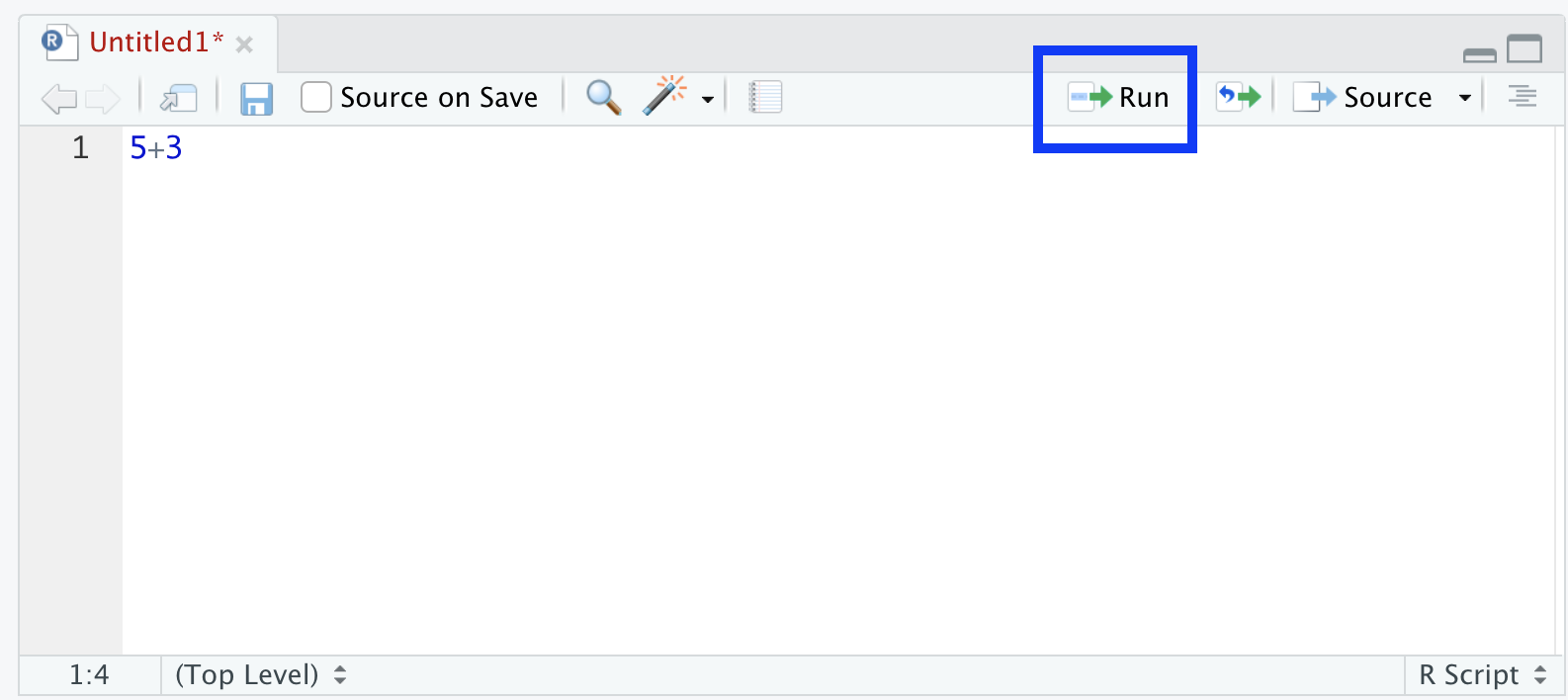
Figure 6.2: Run Button
By clicking Run, the code is sent to the Console to be executed:
The other way to execute code is through using shortcuts. On a Mac, if you click on a line of code, and then press Command + Enter, then that line of code will be sent to the console. On a PC, this is Ctrl + Enter. If you want to run multiple lines, you can simply highlight the lines you want to run, and then press either Command + Enter or Ctrl + Enter and then R will execute all of those lines of code in sequential order.
Just like in Stata, you can do multiplication by using *, division by using / and exponents by using ^. In R, the order of operations is controlled by parentheses:
We can also utilize more complicated mathematical functions, like the log function, square root, or absolute value:
If we are ever unsure what a function does, we can utilize the help files. For example, for the log function, we may not be sure what the base is. To bring up the help file for the log function we can type:
?logReading the help file will inform us that by default, the base of the log function is equal to \(e\), which implies the default is to take the natural logarithm. Additionally, the help file tells you how to compute logarithms for different bases, such as base 10.
As in Stata, it will be helpful to document your code. When doing empirical projects, you want to be able to go back to the code at a later date and quickly understand what the code is doing. Comments are essential for this. Again, comments are lines within a script that are not meant to be run. They are there to describe what the code is doing.
Any line with a # at the beginning is commented out. If you don't comment out descriptions of the code, then R will try to execute them, leading to errors in the output. So, for example, imagine I want to calculate the hypotenuse of a particular triangle, with sides of lengths 5 and 4. The code below does this, while also documenting what the code is doing.
#Calculate the hypotenuse of a triangle
#One side = 5
#The other side = 4
#The hypotenuse is:
sqrt(5^2 + 4^2)
[1] 6.403124Now imagine I forgot to comment out the first line of description. Let's see what happens
Calculate the hypotenuse of a triangle
#One side = 5
#The other side = 4
#The hypotenuse is:
sqrt(5^2 + 4^2)
Error in parse(text = input): <text>:1:11: unexpected symbol
1: Calculate the
^It reports an error because Calculate is not executable code in R. By placing a # at the beginning of the line, however, R will ignore this line and not try to execute it.
6.4 Objects
Objects in R are any pieces of information:
- A number, called ``numeric'' in R (e.g. \(5.23\))
- A text string, called ``character'' in R (e.g. "UCSD is awesome")
- A dataset (e.g. we will look at a resume dataset soon)
- Many more!
R can store objects with a name of our choice. In order to create an object, you can use the assignment operator <-. For example, if I want to create an object named graduationdate, which is equal to 2010, I would type
graduationdate <- 2010This will add to the Environment (top right window) a new object called graduation date, which is equal to 2010. Instead of the assignment operator <-, we can also use =. While it is generally suggested to use the assignment operator in R when creating objects, the equals sign will also work, as below.
graduationdate = 2010Now that we have this object stored in memory, every time we type the word graduationdate, R interprets the value of 2010. This means we can use our object in calculations. For example, to calculate the number of years between 2022 and the graduation date, we can type:
If we assign a new value to the same object name, then we will overwrite this object (so be careful when doing so).
R can also represent other types of values as objects, such as strings of characters:
school <- "UCSD"We can use the class function to retrieve the type of object
So far, every object we have created has a single value associated with it. Next, we will discuss vectors. A vector represents a collection of information of the same type stored in a specific order. For example, instead of the graduation date of a single individual, maybe we have information on the graduation date of four individuals. This collection of information constitutes a vector. We can create a vector in R by using the function c(), which stands for "concatenate". For example, let's create a vector of graduation dates:
#Create a vector of graduation dates
graduationdate <- c(2010, 2009, 2015, 2001)
graduationdate
[1] 2010 2009 2015 2001We can perform calculations on a vector as well. For example, for each student, let's compute the number of years between graduation and the year 2022.
graduationdate is a numeric vector, because each element is a number. We can also create character vectors, where each element is a word. For example, imagine next we want to create a vector that contains information on the school of each of our four individual students. We could type:
#Create a vector of schools
school <- c("UCSD", "UCB", "UCLA", "UCR")As in Stata, whenever you reference character values (also known as string values), you put these values in quotation marks. This lets R know that this information is composed of characters, not numbers.
One important note is that a vector cannot hold information of different types. In other words, you can't have a vector that holds both numeric and character values. For example, imagine we try to combine our two vectors using the c() function:
Now it may look like we have succeeded, but look carefully at the first few entries. Each entry is surrounded by quotation marks. R has changed the numeric entries to character entries.
Lastly, one helpful note is that we can use arithmetic operations between vectors. For example, imagine we have a vector of individual incomes and a vector of planned raises for each individual. To get to the total income after the raise, we can add these two vectors together.
#Create a vector of income
income <- c(65, 70, 20, 100)
#Create a vector of raises
raise <- c(5, 10, 3, 20)
#Calculate current income for each person
income + raise
[1] 70 80 23 120In terms of data analysis, we can really think of vectors as a variable. Our first variable was graduationdate, our second variable was the school. Often, in data analysis, we want to compute some summary statistics of our variables. In R, there are a host of functions that help summarize numeric vectors:
-
length(): length of a vector (number of elements) -
min(): minimum value -
max(): maximum value -
range(): range of data -
mean(): mean value -
sum(): total sum of the elements
Let's try some of these out so that we can get a good sense of what these functions are doing:
Notice that many of these functions require a numeric input. For example, it does not make sense to take the average of school:
mean(school)
Warning in mean.default(school): argument is not numeric or
logical: returning NA
[1] NAHowever, it does make sense to ask, how many elements are there in the vector school?
6.5 Working Directory
In this section, we are going to discuss how to load data. First, we will introduce how to set your working directory in R. Then, we will load in the datafile named resume.csv. To remind you, this is a dataset of fictitious resumes that were sent out by Bertrand and Mullainathan (2004) in order to identify labor-market discrimination. We are going to study callback rates for applicants with white-sounding names and applicants with Black-sounding names. If we find any differences in callback rates, it must be driven by race, as all other factors between the resumes are designed to be similar by the researchers.
To remind you from the Stata chapters, the working directory is the "address" on your computer where R looks for data. It is also the address where it outputs results, such as datasets, figures or tables. In order to work with data in R, you need a good understanding of the working directory. To retrieve the current working directory in R, you can type:
To set your working directory, we use the setwd() function. You should set the working directory to wherever the data is located. For this chapter, you want to set your directory wherever you have placed the data file resume.csv. For example, on my computer, I would type:
setwd("/Users/davidarnold/Dropbox/Teaching/EP5Bookdown/data") Because this is the folder in which I have placed the data. If you are uncertain how to get this address in R, you can also find the Session tab at the top of the screen. If you click on Session, one of the options will be Set Working Directory. You can then navigate to Choose Directory. This will allow you to navigate through your folders as you usually would. Click the folder in which you have stored the data and press Open. This will then change your working directory to that folder. Even better, the code used to change the directory will be printed in the console. You can just copy and paste that snippet of code into your R script so that next time you open up the script you can just run the line of code instead of manually setting up the directory.
6.6 Dataframes
Now that we have set the working directory, we can actually load in our data to start exploring it. To do this, we will use the read.csv() command. This is the command used to load comma-separated values files.
resume <- read.csv("resume.csv")If we look to the environment now, we will have a dataset of 4870 observations (obs.) and 5 variables. If you click on the blue arrow next to the data frame, the variables (and the first few values), will be revealed, as in Figure 6.3

Figure 6.3: Loading a Data Frame
If you click on the name of the data frame, RStudio will open up a spreadsheet of all the data. This is similar to how we would use the browse command when using Stata. This allows you to look through the raw data and understand what the various variables are and what values they may take.
There are also a few ways to summarize information about the data frame. For example ncol(), retrieves the number of columns. nrow() retrieves the number of rows In this example, there are 5 variables, so there will be 5 columns. There are 4,870 observations, so there are 4,870 rows. One thing we can do to quickly get a sense of the data is to type summary(resume). This provides some simple summary statistics for each variable in the data frame.
summary(resume) X firstname sex
Min. : 1 Length:4870 Length:4870
1st Qu.:1218 Class :character Class :character
Median :2436 Mode :character Mode :character
Mean :2436
3rd Qu.:3653
Max. :4870
race call
Length:4870 Min. :0.00000
Class :character 1st Qu.:0.00000
Mode :character Median :0.00000
Mean :0.08049
3rd Qu.:0.00000
Max. :1.00000 For numeric variables, this command provides the min, max, 25th percentile (called 1st Quartile), median, mean, 75th percentile (called 3rd Quantile) and max. For character variables, R just reports the length (i.e. the number of observations). In this dataset, the variable X is just a variable that records the observation number, which goes from 1 to 4870. firstname is the name on the application. sex is either female or male. race is either white or Black. call is our main outcome of interest. It is equal to 1 if the fictitious application received a callback for an interview. It is equal to 0 if the fictitious application did not receive a callback.
Although we have already shown how to browse the raw data, it is sometimes inconvenient to look at the entire data frame, particularly when you have a very large dataset. However, it is often helpful to get a small snippet of the data. To do this, we can use the head() function. This shows you the first six observations in the data frame:
head(resume) X firstname sex race call
1 1 Allison female white 0
2 2 Kristen female white 0
3 3 Lakisha female black 0
4 4 Latonya female black 0
5 5 Carrie female white 0
6 6 Jay male white 0Similarly, we can use the tail() function to show the last six observations in the data frame.
Next, let's talk about a big distinction between R and Stata. In Stata, we always had one data set. This makes it easy to reference variables: we just type the variable name. For example, if we had wanted to take the mean of the variable call in Stata, we would have typed sum call.
In R, however, you can load multiple data frames at a time. This is actually a really nice feature of R, especially when you are trying to merge data frames together. What it means, however, is that whenever you reference a variable, you need to reference both the variable name, as well as the data frame that it comes from. For example, to reference the variable call within the data frame resume, we type resume$call.
For example, if we wanted to look at the first six observations, but only for call, we would type:
head(resume$call)[1] 0 0 0 0 0 0It is a very common mistake for beginners to forget to specify both the data frame and the variable. This can lead to some confusing errors, so always make sure that you are specifying both the data frame and the variable in R.
Now that we have our data loaded and we understand how to reference variables, let's begin to explore the data. First, let's get a sense of the callback rates for these fictitious applicants. Remember, our variable call is equal to 1 if the resume received a callback for an interview. Therefore, if we take the average of this variable, then this value will be equal to the fraction of individuals who received a callback. If you don't follow this logic, make sure to flip back to Chapter 1.5 to review why this is true.
We already know how to take the average of a vector, we use the mean() function. But a column in a data frame is just a vector. So we can use this function to find the callback rate:
So around 8 percent of all applicants received a callback for an interview. Low callback rates are pretty common in these settings. Next, let's look at our other main variable of interest. To get the distribution of race we can use the table() function, which prints out a table of frequencies:
So there are equal numbers of white and Black applicants. This was by design. The researchers were particularly interested in understanding racial disparities in callback rates. Therefore, they designed the experiment to have equal rates of white and Black applicants.
Lastly, let's talk about how to save a data frame. In most empirical projects, we won't have such a clean data frame to start with. We may need to drop certain observations, clean certain variables, and overall, make many changes to our data. It is never a good idea to overwrite your raw data, so after you are done cleaning your data, you should save a new data file.
To save a csv file in R, you can use the write.csv function:
write.csv(resume, file="resume1.csv")This will save the data frame resume which is currently in memory as a csv file named resume1.csv. This file will be saved in your working directory.
There is also another format for data that is common in R: "RData". You can save your file as and RData file by using the save() function.
save(resume, file="resume1.RData")There is often not a strong argument between saving as a csv file verse an RData file. In general, however, csv files are often more portable across different statistical programs. Most of the data we will be using in the R section of the course will therefore be stored as csv files.
6.7 Logic
Just like in Stata, logical statements will be a key concept in this section of the course. To remind you, a logical statement is any statement that is either true or false. In R, there is a special type of object, called logical objects, which are objects that take on either the value TRUE or FALSE.
Sometimes we may want to subset our data to observations in which a certain statement is true. For example, maybe we have a dataset that has individuals from many states, but we only want to analyze data for California. In this case, we may want to subset to observations such that the logical statement "Individual resides in California" is true. We are often going to be using logical statements in R to manipulate our data.
So how do we create these objects that are either true or false? We use logical operators. We have seen many logical operators in the Stata portion of the class. For example, the double equals sign == is a logical operator that tests whether two things are equal. Here is a list of all the logical operators we will be using throughout the R portion of the course:
!-- not&-- and|-- or==-- equals!=-- not equals>-- greater than<-- less than>=-- greater than or equal to<=-- less than or equal to
Now that we've written out the different logical operators, let's see how to use these in R. To begin, let's start with a simple logical statement: "5 is equal to 6". The way we type this in R is we type 5==6. This statement is of course false, so if we type this into R it should yield FALSE.
If instead, our logical statement is "5 is equal to 5", then this statement should yield TRUE.
Now let's write out "5 is not equal to 6", by using the ! operator.
But "6 not equal to 6" is of course FALSE:
Now let's try to understand the & operator. We use the & operator when we want to test if two statements are both true. For example, let's imagine we have an individual who is 18 and lives in California. Then the statement "This individual is 18 and lives in California" is true. The way we might type this in R is age==18 & state=="CA". Now let's do an example in R. Imagine we want to retrieve the answer to "5 is equal to 5 and 5 is equal to 6". In R we would type 5==5 & 5==6. This statement is false because 5 is not equal to 6. If one of the statements is false (5==6) then the whole statement is false (5==5 & 5==6).
In contrast, the statement "5 is equal to 5 and 5 is greater than 4" is true because both of the statements individually are true.
Now let's discuss or statements. For an or statement, we are instead testing whether either statement is true. For example, if our statement is "5 is equal to 5 or 5 is equal to 6", then this is true if either 5==5 | 5==6.
So far we have only applied logic to numbers in R. However, we can also apply this to vectors in R. This will be particularly important when we turn to data. We will often want to apply logical statements to variables in our data.
As a simple example, let's create a vector of graduation dates that has four entries:
graduationdates <- c(2010,2001,2019,2003)We can apply logical statements to the entire vector as well. For example, imagine we want to know which graduation dates are after 2010. We can type:
This outputs another vector of four entries. Each entry tells us whether the corresponding entry in our graduationdates vector is greater than 2010. For entries 1, 2, and 4, this statement is FALSE. For entry 3, this statement is TRUE.
Next, let's learn how to compare two vectors. For example, imagine we have the vector of birth years that are supposed to be for the same individuals as in the graduation data:
birthyears<- c(2016, 1980, 1996, 1990)By looking at this vector, it is clear something went wrong for the first individual. The individual is reported as being born in 2016 but graduated in 2010. There must have been some sort of data entry error for this individual. While we can quickly identify this mistake in our small data, imagine we have thousands of individuals. It won't be possible to identify all of the errors by manually going through the data.
Instead, we can simply test whether there are birthyears in the data that are greater than graduationdates
For this logical statement, the first element of birthyears is compared to the first element of graduationdates. Since 2016 is greater than 2010, the first element of the resulting logical vector is TRUE. The second element of birthyears is compared to the second element of graduationdates. Since 1980 is less than 2001, this statement is FALSE.
So far, we have just observed the output of these logical statements (i.e. the output is displayed in the console). But imagine we want to save the output because we are using it in future analyses. For example, imagine we want to drop observations in which the birth year is greater than the graduation date. Well, we can simply store the output in a new vector by assigning it a name:
problem <- birthyears > graduationdatesNow we have a vector problem that has been added to our environment. If we check the class of this vector we will see that it is a logical vector.
Now, the way logic functions in R is that it can function as a numeric variable. Specifically, the value TRUE is equal to the number 1. The value FALSE is equal to the number 0. Therefore, we can treat logical statements in the same way we've treated binary indicator variables in the past. For example, imagine I would like to compute the fraction of individuals for which there is a problem in the data, which is defined as a birth year greater than a graduation year. All I have to do is take the average of the problem vector.
Why does this get us the right result? Because the problem vector is equal to TRUE FALSE FALSE FALSE. R will interpret this vector as 1 0 0 0. The mean value of this vector is therefore equal to 0.25. In other words, for 25 percent of individuals, there is a problem in the data. If you prefer to have the vector in numeric format instead of logical, you can also change it yourself by using the as.numeric() function:
This just changes how the information is displayed to you in R, not the actual information itself.
6.8 Subsetting Vectors
Often we want to extract certain elements of a vector, which is known as subsetting. In R, to subset a vector we use []. Inside the [] we can place a number to extract a certain element. For example, if we type graduationdate[3], we would extract the third element of the vector graduationdate. This is referred to as indexing. In this example, 3 is the index number.
We can also use logic to extract certain elements. For example, in general, if we type vec[logical statement], then only the elements for which the logical statement is true will be extracted. This will be especially useful when using data because it is common we want to extract elements that meet a certain condition, for example, individuals above the age of 18, or counties located in California, etc.
To understand how to subset vectors in R, let's run through a few examples. First, let's re-create our graduationdates vector.
graduationdates <- c(2010,2001,2019,2003)The third entry of graduationdates is 2019. If we want to extract this entry, we can just type
Instead of extracting an element, you can also use what is referred to as negative indexing. If you put a negative in front of the index number, then you get all elements of the vector, except that element. For example, let's see what happens when we type graduationdates[-3]
The output is another vector, but now only composed of three elements. The new vector has dropped the third element of graduationdates.
You can also use indexing to subset multiple elements of a vector. For example, imagine we would like to extract the first and third elements of the graduationdates vector. To do this, we create a vector of indices.
If you recall, c(1,3) is a vector. The c() function concatenates 1 and 3 into a vector. The way R reads the statement above is "extract from the vector graduationdates, the 1st and 3rd element.
Now that we understand how to subset vectors using numbers and vectors, let's learn how to index using logic. Instead of entering a vector of numbers as the index, we can directly enter a vector of TRUE and FALSE. Only the elements for which the entry is TRUE will be extracted. To see how this works, let's try to understand the example below:
The vector c(TRUE, FALSE, TRUE, FALSE) is TRUE for the 1st and 3rd element. Therefore, only the first and third elements have been extracted. A more common way you might see this used is through another vector or variable. For example, imagine we also have a vector that contains the school that the student attended.
school <- c("UCSD", "UCB", "UCLA", "UCR")Imagine we want to retrieve the graduation date for the student who attended UCSD. If we type school=="UCSD", we will get a vector of 4 elements:
Only the first element is TRUE. Therefore, if we use this vector to subset the graduationdate vector, we will retrieve the graduation date of the student who attended UCSD.
Next, let's turn from our simple examples to our empirical application for this section: correspondence studies. First, let's re-load the data on fictitious applications from Bertrand and Mullainathan (2004).
resume <- read.csv("resume.csv")Remember, we can really think of each variable in a dataframe as a vector. Therefore, we don't really need to learn anything new. We just need to apply what we have learned so far to this new data structure.
First, let's talk about how to use logical subsetting on a variable. What happens if we type resume$race=="black". Well, resume$race is a vector with 4,870 elements. It takes on values "white" or "black". Therefore, resume$race=="black" is also a vector with 4,870 elements. The first element is TRUE if the first individual in the dataset had a Black-sounding name. The first element is FALSE if the first element had a white-sounding name. You can convince yourself of this by typing:
vec <- resume$race=="black"And then studying the resulting vector vec. What happens if we then add a function around this vector? For example, if we type sum(resume$race=="black"), then R should add up all the values of the vector resume$race=="black". Recall, R interprets a value of TRUE as equal to 1, and a value of FALSE as equal to 0. So if we type sum(resume$race=="black"), we will just retrieve the total number of applications with Black-sounding names.
We can subset one variable using a logical statement built from another variable. For example, imagine we want to compute the callback rate for Black applicants. Therefore, we want to compute the average of call only for individuals such that race=="black". In R, we can write out this statement as follows:
It is easiest to interpret this line of code by starting at the indexing step. [resume$race=="black"] restricts to observations for which the applicant is Black. resume$call[resume$race=="black"] is the vector call, but only restricted to the observations for which the applicant is Black. Finally, by placing the entire block inside the mean() function, we are computing the average of resume$call for applicants such that resume$race=="black". If we want to compare to white applicants, we can simply type:
6.9 Subsetting Data Frames
Next, we will discuss how to subset data frames. To illustrate this concept, we are first going to generate a small data frame in R:
students <- data.frame(school=c("UCSD", "UCB", "UCSD"),
graduationdate=c(2010, 2019, 2015))To understand what the code above produced, let's look at the dataframe student:
This data frame has two variables: school and graduationdate. The first column of the data frame corresponds to school and the second corresponds to graduationdate. The data frame has three total observations. To extract a specific value of the data frame, we can again use indexing. When using indexing with a vector, we could specify a single number, and that would pluck out that element. Now, with a data frame, we need to specify two numbers. First, we will specify the row we would like to extract and then we will specify the column. For example, to extract the value in the 3rd row, 1st column, we would type:
It outputs "UCSD" because the the third student in the data frame went to UCSD and the 1st column in the data frame corresponds to the variable school.
Instead of extracting specific elements of a data frame, you can also extract entire columns and rows. For example, to extract the first-row type:
The second entry in the [,] always corresponds to the column. Since it is blank, R extracted all columns for the first observation. Similarly, you can extract a single column by leaving the rows portion of the index blank. For example, to extract the second column, type:
Now, since the row index is blank, R extracts values from all rows, but just the second column. You can also use a vector to specify what observations or columns you would like to retrieve. For example, imagine we think there was an error with recording the graduation date for the second observation in our data frame. To be careful, we would like to drop this individual from the data frame. In other words, we want to extract rows 1 and 3 of the data frame and leave out row 2. To do this, we can subset by specifying a vector of indices. The vector will contain the indices of every row we want in the final data frame:
We can do the same thing with negative indexing, as seen below:
Next, let's discuss how to use logic to subset data frames. For example, imagine we want to extract all individuals that went to UCSD. In other words, we only want individuals such that students$school=="UCSD" is TRUE. Remember, if we type this into R we will get a vector of TRUE and FALSE statements:
Then, just like with vectors, if we use this logical statement to subset, we will only retrieve observations such that the statement is TRUE. In this case, this statement is TRUE for the first and third observations:
Indexing data frames and vectors in this way is a useful skill that will be portable to other software programs that you may encounter in the future. However, in R, there are often easier solutions to subsetting data. For example, the function subset is often used to subset data frames. When we learn about the tidyverse in a future chapter, there will be a function that is again useful for subsetting.
The general syntax for the subset command is:
The resulting data frame will be a subset of the data frame named df restricted only to the observations for which the logical statement after the comma is TRUE. For example, to create a data frame of UCSD students, we could type:
Remember, to save this data frame as a new object in R, you will need to assign it a name.
ucsd_students <- subset(students,students$school=="UCSD")6.10 Conclusion
Now, let's put everything that we've learned in this chapter together to study discrimination in hiring practices. To get started, let's load in the resume data.
resume <- read.csv("resume.csv")When we are exploring a new data frame, it is often helpful to get a sense of the variables and the values they take. Let's look at the first few observations in the data in order to remind ourselves what is in the data:
head(resume)
X firstname sex race call
1 1 Allison female white 0
2 2 Kristen female white 0
3 3 Lakisha female black 0
4 4 Latonya female black 0
5 5 Carrie female white 0
6 6 Jay male white 0Our main outcome of interest is whether an individual received a callback for an interview. In the data frame, a 0 represents the resume did not get a callback. A 1 represents the resume did get a callback. Because the data is stored in this way, we can simply take the average of the variable call in order to retrieve the overall callback rate:
Remember, whenever we specify a variable, we need to specify both the data frame as well as the variable name. As we will see later, it is often helpful to have multiple data frames loaded into memory in R.
In this experiment, we want to understand whether the callback rate varies by race. Before proceeding, let's look at the distribution of race across applications:
There are 2435 resumes with white-sounding names and 2435 resumes with Black-sounding names. Remember, these are fictitious resumes, and the experimenters designed the study so that there would be an equal number of applications for white and Black applicants.
Note that we could retrieve the same information using logic. When we type a logical statement, R will return a logical object that is composed of TRUE and FALSE. Whenever R sees TRUE it interprets a 1, and whenever R sees FALSE it interprets a 0. For example, if we type:
We get a value of 2435. Why? Well, resume$race=="black is a vector of length 4870. Half of the elements are TRUE while the other half are FALSE. The sum() function adds up all the values of a vector. All the TRUE values are equal to 1 and all of the FALSE values are equal to zero. Therefore, it is simply counting up all the applications for which the statement is TRUE.
Now, let's get to the main analysis, which studies whether callback rates vary by race. To do so, let's first find the callback rate for applicants with Black-sounding names. To do this, we will again utilize logic:
Here we are using indexing. [resume$race=="black"] subsets to Black applicants. Because we have put this inside mean(resume$call[]), then R will retrieve the average of the resume$call vector, but restrict to Black applicants. As we can see, about 6.4 percent of Black applicants receive a callback.
Let's now compare this to white applicants:
Before interpreting these findings, it is helpful to point out that there are a couple of different ways we could have performed the analysis. For example, sometimes it is helpful to generate different data frames for subsets of your data. We could have done this through indexing or through the subset function:
For example, to create a data frame restricted to Black applicants we could type:
resume_blacknames <- resume[resume$race=="black",]
resume_whitenames <- resume[resume$race=="white",]Then, to calculate the callback rate for Black applicants, we should just reference this data frame:
Now that we have performed the main analysis, let's summarize our findings. Around 9.7 percent of white applicants receive a callback, while only 6.4 percent of Black applicants receive a callback. Therefore, there is a 3.3 percentage point disparity in callback rates. This is a substantial disparity. The baseline callback rates are quite low in this setting. A 3.3 percentage point disparity implies white applicants are more than 50 percent more likely to receive a callback relative to Black applicants:
\[ \text{Percent Increase in Callbacks for White Apps}=\frac{9.7-6.4}{6.4}=0.516 \] This highlights a stark disparity in labor-market outcomes. Given the empirical design: randomizing race across applications, these disparities cannot be driven by other factors that employers take into account when making hiring decisions. They are due to the names associated with the applications, and how those names proxy for race.
This empirical design has become widely popular. It has been used to study discrimination across other demographics, for example, gender, sexual orientation, and disability status. It has also increased in scope, with recent experiments sending out thousands and thousands of fictitious resumes in order to understand discrimination at some of the largest employers in the U.S (see Kline, Rose, and Walters 2022).10
Function Descriptions
Setup Functions
getwd()–- retrieves the current working directorysetwd("pathname")-- sets the working directory to whatever is contained in pathname. For example, if I typesetwd("Users/davidarnold/Desktop"), then my working directory will be set to my desktop.<--- this is called the assignment operator. It assigns some value to an object. This can be used to create numeric objects, character objects, vectors, as well as dataframes.read.csv(csvfile.csv)-- reads in a csv file into R. To save the csv file as a dataframe, assign it a name.df <- read.csv("csvfile.csv")
Data Exploration Commands
nrow()-- retrieves number of rows in a data frame.ncol()-- retrieves number of columns in a dataframesummary(dataframe)- lists all variables in the dataframe. For numeric variables, computes some key quantiles.names(dataframe)- retrieves names of all columns in the dataframemean(dataframe$varname)-- retrives the mean value ofvarnamewhich is a variable inside the data framedataframe.table(dataframe$varname)-- retrieves a table of frequencies for the variablevarnamewithin the data framedataframe. This can be used for string variables as well as categorical variables.